Making CIDR: A History
by Leo Vegoda

“It is not necessary to change. Survival is not mandatory.” – W. Edwards Deming
Deming’s joke hides a tough truth. We have to adapt because the world around us is always changing. That is the situation the internet’s architects found themselves in at the start of the 1990s.
The ARPANET had become the NSFNET when it moved from Defense Department oversight to the National Science Foundation. It became the internet in 1991 when the US government allowed anyone to connect. As soon as business could connect, rapid growth became inevitable. That growth threatened the architects’ initial addressing plan.
The threat was the result of the distribution system in place for doling out “blocks” of addresses. The system in place at the time subdivided all the available IP addresses into three flavors. Those flavors included 16,777,216 (Class A), 65,536 (Class B) and 256 (Class C) addresses. These very different sized packages of addresses left the distributors of them few choices, Any organization with modest-but-not-small address needs could receive multiple Class C blocks (256 addresses each) or one Class B (65,536). Since dealing with multiple small blocks presented its own challenges (and IP addresses were abundant and free) many were simply given Class B allocations. Far more than they needed.
When businesses became involved, demand soared. Soon, there were not enough mid-sized address blocks to support the rate of growth of the internet. In fact, when the Internet Engineering Task Force (IETF) met in San Diego in June 1992 they projected that there were “less than 2 years” of these address blocks left.
They also noted that the routing system was creaking at the seams. Older routing protocols, like EGP and RIP, “were designed for a much smaller number of networks” and the routers deployed at the time were reaching their memory limits.
The story of the design considerations that lead to this situation is an interesting one.
Getting to the Early 1990s
When the Internet Protocol was introduced, it was part of an experiment in computer networking. Computers were slow and expensive. So, the architects divided up the address space into three main areas, called classes. Each class had a limited number of possible networks in it and those networks were all the same size.
This meant the routers would know which network any address belonged to based on the first eight bits of a Class A network, the first 16 bits of a Class B network, and the first 24 bits of a Class C network.
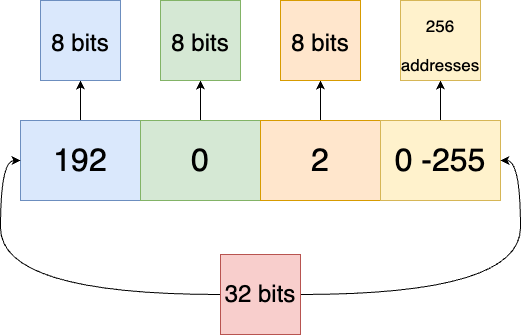
Fig 1. Addresses in a Class C network are identified by the first 24 bits
A router, the specialized computing device that directs traffic across networks, would know that all addresses starting with 192 have 24 bits of network address. This leaves eight bits for host addressing, meaning 256 addresses.
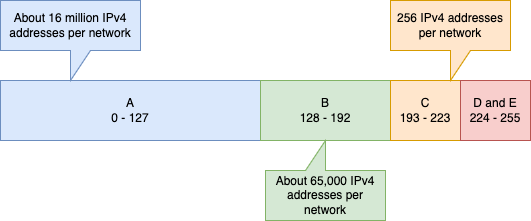
Fig 2. The Class B space was the best for most organization but just 25% of the total space[1]
Class D was reserved for a special technology called multicast: a way to send a packet once and have it go to multiple destinations. It was widely used in video delivery and financial services.
Class E was reserved for future use and has never been officially allocated.
This architecture had two key benefits. Routers could make decisions more quickly. It also made deciding how much address space an organization needed simpler. In most cases, the answer would be obvious.
The downside was that the Class B space was the best available fit for most organizations connecting to the internet. That said, most organizations did not make efficient use of their Class Bs because it was frequently larger than their needs. Plus, as there were just over 16,000 Class Bs, there was a very real limit to future growth unless the architecture was changed.
CIDR’s Architecture
By 1993 the IETF had a new addressing architecture. Among the needs it addressed was the ability to assign more accurately appropriate-sized blocks of addresses to networks needing them. They called the new architecture Classless Inter-Domain Routing, or CIDR (pronounced cider).
It was based on aligning addressing – the numbers used by network interfaces – with topology. This meant that IPv4 addresses would be assigned hierarchically, based on the shape of the network. In other words, this is the origin of the IPv4 addressing policy concept of aggregation.
This architecture made some assumptions. While these assumptions were made before relatively cheap computing or international connectivity, they broadly still hold true today.
These included:
- In most cases, network topology will have a close relationship with national boundaries. Continental aggregation is useful because continental boundaries provide natural barriers to topological connection and administrative boundaries.
- There was a “need for additional levels of hierarchy in Internet addressing to support network growth.
The new architecture got rid of the fixed class boundaries. A really big network could have just seven bits of network prefix – the equivalent of two Class A networks. Similarly, a very small network could use just two addresses – 31 bits of network.
This led to better fitting address allocations to networks. In 1996, the newly formed Regional Internet Registries allocated networks with a 19 bit prefix by default. This was the equivalent of allocating 32 Class Cs and a total of 8,192 IPv4 addresses.
Over time this minimum allocation continued to shrink.
More Routing!
There is an inevitable tension between making more efficient use of the limited IPv4 space and routing.
In December 1992 there were 8,561 routes advertised. This was almost 50 times the number reported about four years earlier, in July 1988. By 2014 this had reached about half a million. In March 2023 we are approaching a million IPv4 routes.
This is a consequence of the business impact of the greater precision available with CIDR. It doesn’t just allow more networks to connect to the internet. Networks can also use the same technology to influence how traffic gets to them.
Border Gateway Protocol, the routing protocol that glues the internet together, tries to find the shortest path to a destination. But it will always prefer the most specific route to an address. If there are two paths to the same address but one advertises just 256 addresses while the other advertises 8,192 addresses, the path to the block of 256 addresses will win. This is called deaggregation.
Deaggregating enables traffic engineering. Networks can break up their addresses and have traffic for different groups of addresses take different inward routes. They do this to have traffic come in over cheaper transit providers or to improve the experience of specific customers.
But the same feature of BGP can cause problems. For instance, in 2008 Pakistan Telecom announced some of YouTube’s IPv4 addresses. Their more specific announcement caused a temporary service outage.
Some networks use the service impact of this kind of incident as a justification for announcing multiple routes to small blocks of addresses instead of just one to the whole address block. The advantages accrue to the address holder but the costs are borne by all other networks.
APNIC publishes a regular report detailing how networks deaggregate their address space. In March 2023, one network was announcing almost 9,500 more routes than needed for the addresses they use. This is more than the total number of routes reported on the internet in December 1992.
In March 2023 there are about 75,000 internet networks that manage their own routing. About 52,000 advertise a more specific prefix. The average number of addresses advertised is just over 3,000 addresses.
What’s Next?
In the early 1990s the internet transitioned to a decentralized management structure and new architecture in a couple of years.
Change is harder in the 2020s. There are many more participants and most of them aren’t involved in the technology of the internet itself.
One technology might limit the need for deaggregation: RPKI. Its Route Origin Authorization object can tell other networks how specific routing announcements will be. But RPKI is a way to digitally sign assertions not to force compliance. Networks don’t have to use RPKI and NIST shows that about 60% don’t.
One program that might help is the Internet Society’s MANRS. It defines four sets of actions designed to improve the security and resilience of the Internet’s global routing system. By working with network operators, IXPs, CDN and cloud providers, and equipment vendors they drive improvement through some of the most important organizations on the internet.
The warning from 1993 was to “consider the memory requirements [from more routing] information.” The day where some networks see more than a million routes is fast approaching. Some networks will choose to buy bigger, better routers. Others will need to apply filters, much like we saw in 2014 when we crossed the half a million routes boundary.
“Survival is not mandatory.”